For a traditional app, the attack surface is the API. For an AI agent, it's everything the agent reads. The moment a model can act — call a tool, retrieve a document, hand off to another agent — every input channel becomes a potential instruction. And unlike a SQL injection, a prompt injection doesn't need to look like an attack. It just needs to look like text.
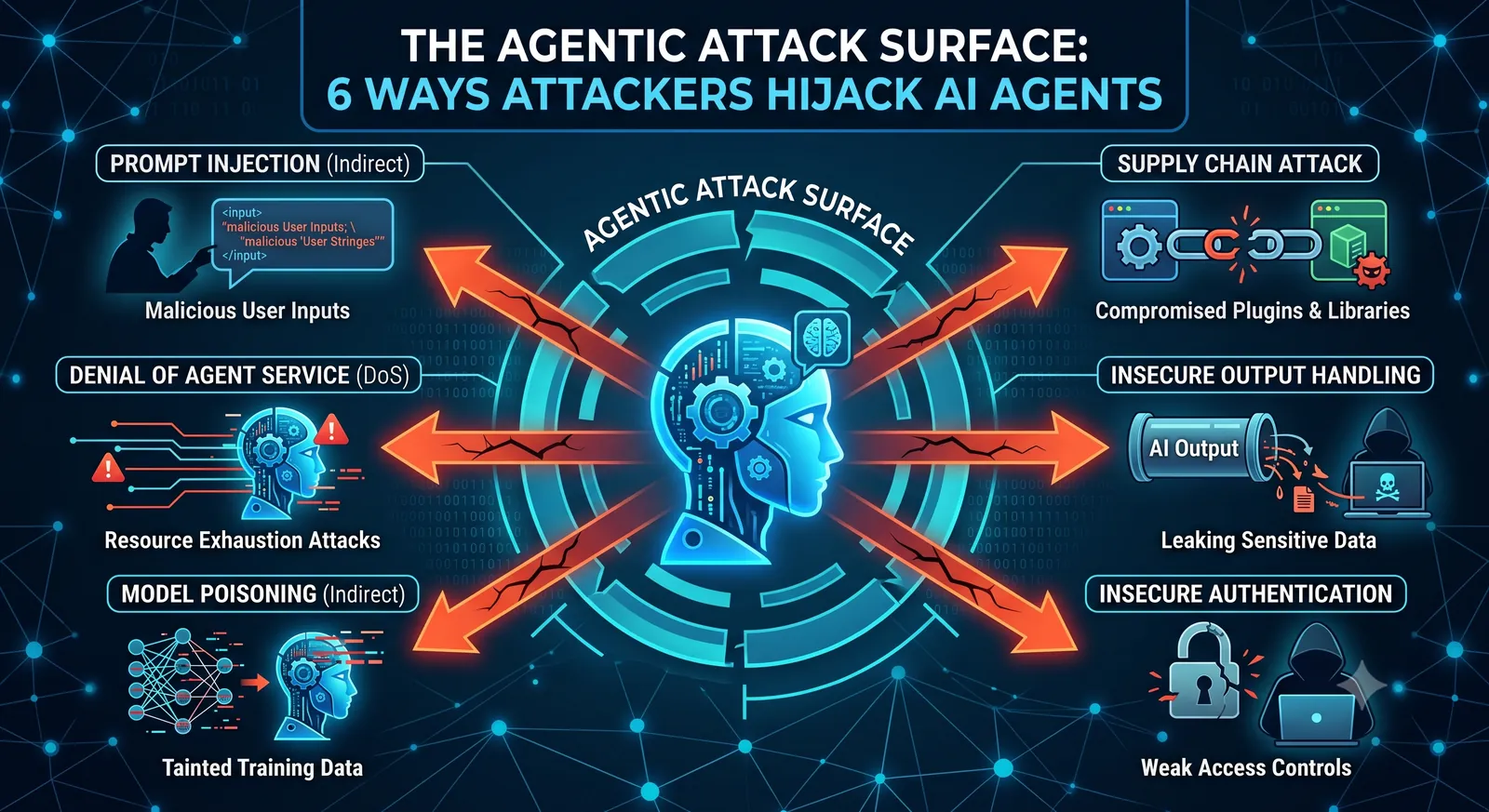
Most security tooling watches one door: the prompt. But an agent has six. Below is the full surface, the threat at each, and what inspecting it actually requires.
The core shift: in agentic systems, data and instructions share a channel. Any content an agent ingests — a document, a tool result, another agent's message — can carry commands. Defense means inspecting every surface, in and out.
1. Prompt — direct injection & jailbreaks
The most familiar surface. A user (or an upstream system) crafts input that overrides the agent's instructions — "ignore previous directions and…". Jailbreaks chain framing, role-play, and encoding to slip past naive filters.
Regex and keyword filters catch the obvious cases and nothing else. Real coverage needs a forensic classifier that scores intent, not strings — and that raises its scrutiny when an agent starts behaving abnormally.
2. RAG / retrieval — the poisoned document
Retrieval-augmented generation trusts whatever it retrieves. Plant a malicious instruction in a document the agent will fetch, and you've turned the knowledge base into a command channel — no direct access to the prompt required. This is indirect prompt injection, and it's the surface most teams forget.
A poisoned document becomes a trusted instruction the moment your agent retrieves it.
3. Tool / MCP calls — toxic combinations
Once an agent can call tools, the question isn't "is this one call safe?" but "is this sequence safe?" A read from a private datastore followed by a write to an external API is, individually, two legitimate actions — together, an exfiltration path. These "toxic combinations" are invisible to per-call checks.
Governing the tool surface means authorizing each call by rule, enforcing an egress allowlist, and inspecting the call stream for abuse:
# ingress-tool surface
surface: ingress-tool
rules:
- tool: db.query
allow: [read]
- egress.allowlist: [api.internal.svc]
- block: toxic_combination(db.read -> egress.write)
4. Session / memory — slow-burn manipulation
Agents that remember can be poisoned over time. An attacker seeds context across multiple turns, each individually benign, until the accumulated memory steers the agent. Stateless checks miss it; you have to inspect the session, not just the request.
5. Agent-to-agent — unverified trust
In multi-agent systems, one agent's output is another's input. Without verified lineage, a compromised or spoofed agent can inject instructions downstream that no human ever sees. Trust between agents has to be established, not assumed — and every hand-off recorded.
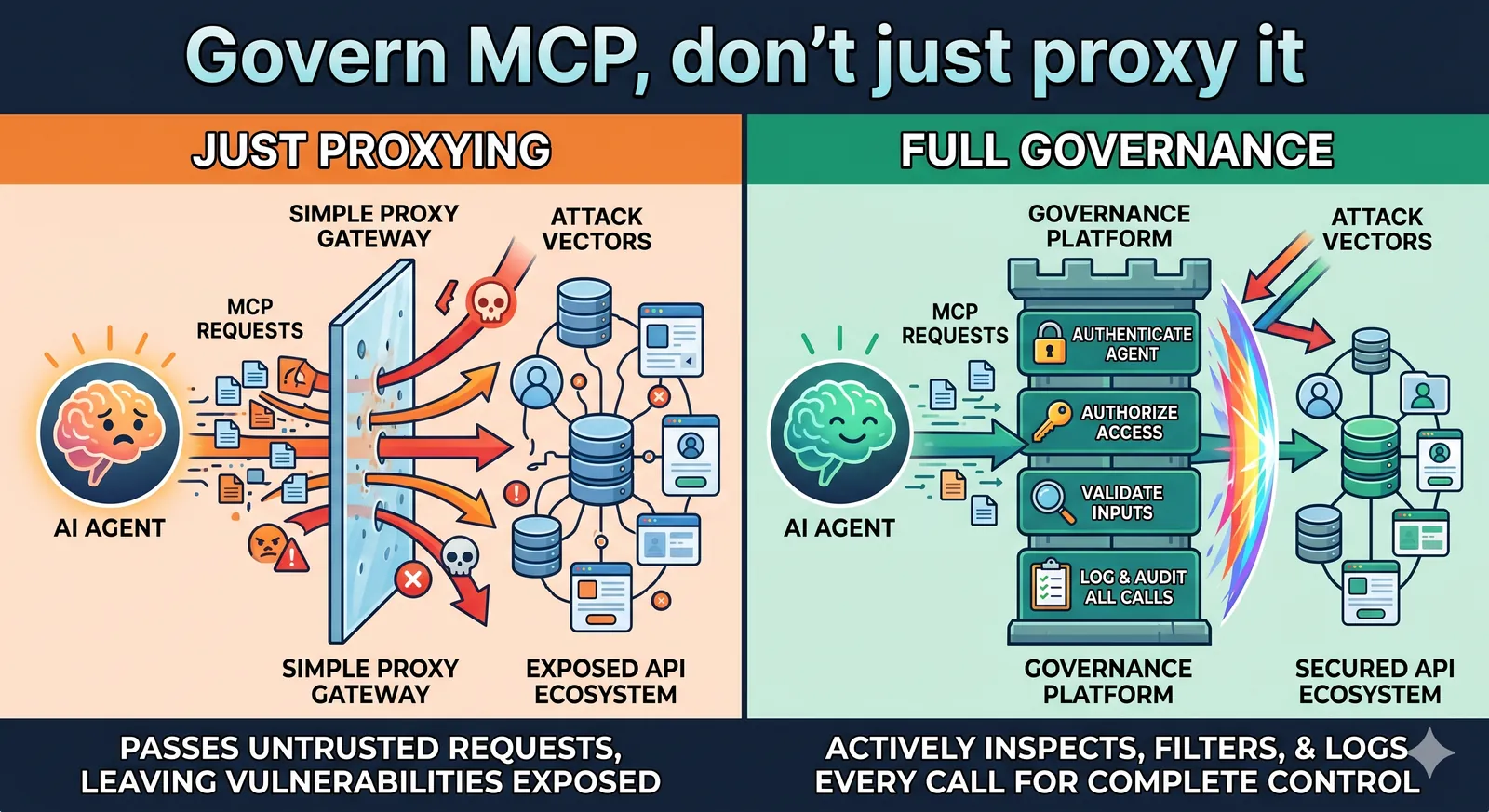
Why point tools fall short: a gateway that only logs prompts is blind to surfaces 2–5. By the time the response is generated, the compromise already happened upstream.
6. Response / egress — the data leaving
The last surface is what the agent says. PII leakage, secrets echoed back, exfiltration smuggled into a tool argument — the response is as much an attack surface as the prompt. Inspecting egress means scanning output, restoring tokenized values safely, and running forensics on everything that leaves.
Inspecting all six
No single control covers this surface. The only defense that holds is layered inspection across every channel, in real time, on the way in and the way out — paired with an engine that adapts as the threat landscape shifts. That's the job Shashu was built for: watch all six surfaces at once, learn each agent's behavior, and raise scrutiny automatically the moment something looks hostile.
Inspect everything. See nothing. That's the bar for governing agents you can actually trust.
Want the full mapping of these attacks to the OWASP LLM Top 10, MITRE ATLAS, and NIST AI RMF? Get the threat-coverage report.